


Caso de estudio
Para esta segunda parte de «Combinando el muestreo intencional y el algoritmo K-means para la captación de usuarios en investigación cualitativa», comenzaremos con un caso de estudio hipotético y generalizable, con la intención de facilitar la extrapolación de la guía presentada a otras instancias específicas. Consideremos que nos enfrentamos al reto de iniciar una investigación cualitativa sobre los hábitos de uso y los puntos débiles de usabilidad de una plataforma de comercio electrónico. Para ser más precisos, esta investigación implicaría la realización de entrevistas en profundidad y test de usabilidad con diversos perfiles de usuarios que usan activamente nuestro e-commerce. Dada la existencia de plazos y recursos de investigación limitados, la selección de la muestra supone un desafío crucial. En concreto, la determinación de la cantidad y las características de los usuarios a entrevistar resulta un aspecto clave. La fase de captación puede influir significativamente en los resultados de nuestra investigación cualitativa y en todas las decisiones que de ella se deriven. El procedimiento de este reto consiste en ejecutar el algoritmo K-means para analizar nuestro público objetivo y, a continuación, aplicar la experiencia del investigador para decidir a quién entrevistar para lograr la saturación teórica.
El requisito previo sine qua non para la aplicación del algoritmo K-means y, en consecuencia, para proceder con éxito a la guía de muestreo intencional estratificado, reside en la obtención de datos pertinentes y de calidad y, en particular, de variables numéricas continuas. No es necesario obtener un conjunto de datos exhaustivo que incluya la totalidad de nuestro público objetivo. Más bien al contrario, bastará con una muestra estadísticamente representativa. En cualquier caso, conseguir un conjunto de datos de calidad y fiable no suele ser un ejercicio fácil, ya que requiere mezclar fuentes de datos primarias y secundarias y, después, pulir los datos. En este sentido, partiremos del supuesto de que nuestra base de datos de comercio electrónico consta de una modesta muestra de 200 usuarios y abarca únicamente cuatro variables:
- El sexo como única variable categórica.
- Edad.
- Ingresos anuales en dólares.
- Customer Engagement Score (CES), que es una métrica que evalúa el nivel de compromiso del cliente basándose tanto en el tiempo que pasa en la aplicación como en el gasto que realiza en ella.
La distribución por sexos en nuestro conjunto de datos es de un 56% de mujeres y un 44% de hombres. A continuación, muestro mediante histogramas la distribución de las tres variables numéricas continuas, que serán las procesadas por K-means.
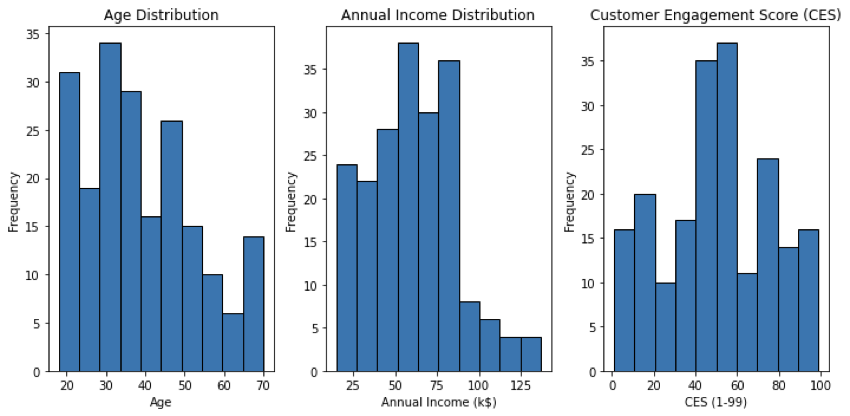
- Para la variable edad, el valor mínimo es 18, el máximo es 70, la media es 38,9 y la desviación típica es 13,9. Este valor de desviación típica indica que existe una variabilidad moderada en las edades. Sin embargo, como podemos ver en el histograma, la distribución es asimétrica.
- En cuanto a la distribución de los ingresos anuales, el mínimo y el máximo son respectivamente 15.000 y 175.000 dólares, la media es de 60.600 dólares y la desviación típica de 26.200 dólares. Una vez más, la distribución está sesgada hacia la derecha, con una pequeña representación por encima de 90.000 dólares.
- Por último, la variable CES. En este escenario hipotético, una puntuación CES de 1 indicaría un compromiso mínimo por parte de los usuarios, tanto en términos de gasto como de tiempo invertido en la aplicación, mientras que una puntuación CES de 99 indicaría un compromiso extremadamente alto por parte de los usuarios, tanto en términos de gasto como de tiempo invertido en la aplicación. Observamos que la media de esta variable es de 50,2 y la desviación típica es de 25,8, por lo que se aproxima más a una distribución normal que la edad y los ingresos anuales.
En la siguiente sección, mostraremos el código Python utilizado para implementar el algoritmo K-means en nuestro caso de estudio. Además, emplearemos una técnica de validación ampliamente reconocida para determinar el valor óptimo de K, es decir, el número final de clústeres: el método del codo o Elbow curve Method (Tomar, 2022).
Aplicación del algoritmo K-means
En esta sección, mostraré y describiré las líneas de código que nos permitirán implementar el algoritmo K-means en nuestro conjunto de datos. En primer lugar, necesitamos importar las librerías necesarias con sus respectivas abreviaturas:
- Pandas
- Matplotlib.pyplot
- Scikit-learn
En cuanto a la biblioteca Matplotlib, tomamos el subpaquete mpl_toolkits.mplot3d para importar el módulo Axes3D, que proporciona herramientas para crear gráficos y visualizaciones en 3D. De Sckit-learn importaremos el algoritmo KMeans.

El siguiente paso es utilizar la función pandas para leer el archivo CSV que contiene nuestro conjunto de datos. Llamaremos al conjunto de datos df, como abreviatura de DataFrame. En el contexto de la biblioteca pandas de Python, un DataFrame es una estructura de datos bidimensional etiquetada. Cada columna en un DataFrame representa una variable o una característica, mientras que cada fila representa una observación o una entrada. Una vez cargado el DataFrame, conservaremos las 200 entradas, pero seleccionaremos sólo las columnas que contienen variables numéricas continuas, que el algoritmo K-means utilizará para agrupar a los usuarios. Dado que el sexo es una variable categórica, la descartamos temporalmente de nuestro análisis.

A continuación, procedemos a trazar la curva del codo, que nos ayudará a detectar el número óptimo de clusters en los que se dividirán nuestros casos. El código comienza con una lista vacía llamada SSE, que significa Suma de Errores Cuadráticos. Esta métrica cuantifica la variación global dentro del cluster, midiendo la cercanía de los casos individuales respecto a los centros del cluster a través de la distancia euclidiana. Los valores de SSE más bajos indican una mejor agrupación. A continuación, se ejecuta un loop para iterar a través de diferentes cantidades de clusters, que van de 1 a 9. Por cada número de clusters se crea también una nueva instancia del algoritmo K-means mediante la función KMeans. El parámetro ‘n_clusters’ se establece para cada número entre 1 y 9, y el parámetro ‘init’ se configura para ‘k-means++’, lo que mejora la inicialización de los centroides de los clústeres. A continuación, el algoritmo K-means se ajusta a los datos de entrada representados por la variable ‘df’, que contiene el conjunto de datos de los usuarios.
El algoritmo asigna iterativamente los casos individuales a los clusters y ajusta sus centroides para minimizar la variación dentro del cada cluster. La inercia, que es la suma de las distancias al cuadrado entre cada caso individual y su centroide más cercano, se calcula utilizando el atributo ‘kmeans.inertia_’. Este valor se añade a la lista SSE, representando la calidad de la agrupación para el número actual de clusters.

Una vez completado el bucle, los valores de SSE se organizan en un DataFrame de Pandas llamado ‘frame’, donde cada fila corresponde a un número de clusters específico y su correspondiente valor de SSE. Este DataFrame se utiliza entonces para visualizar la relación entre el número de clústeres y la inercia.
Utilizando la biblioteca Matplotlib, se genera un gráfico en el que el eje X representa el número de clusters Y el eje y representa la inercia. El gráfico lineal resultante se conoce como curva en codo, y ayuda a determinar el número óptimo de clusters para el conjunto de datos. La curva en codo suele mostrar una tendencia decreciente a medida que aumenta el número de clusters, pero llega un momento en que la tasa de decrecimiento es menos significativa, lo que crea una punta o «codo» en la curva. El valor asociado a dicho codo representa el punto de equilibrio entre lograr patrones más detallados aumentando el número de clusters y mantener la simplicidad manteniendo un número bajo de clusters.
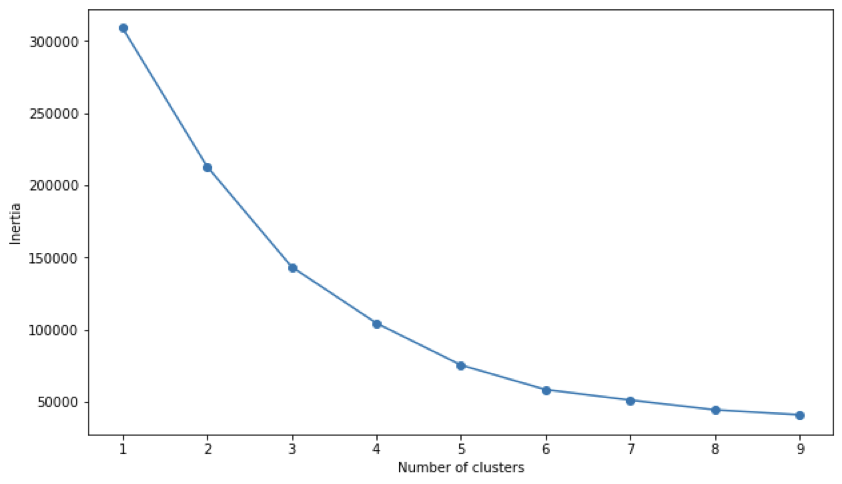
La curva del codo no siempre muestra una punta clara y definida en el que la inercia cambia drásticamente. En nuestro caso concreto, aparece un suave codo en el valor 5 clusters. Esto implica que aumentar el número de clusters más allá de 5 puede significar complicar en exceso el análisis por añadir demasiada complejidad. Mientras que un punto de codo pronunciado suele significar un número óptimo de clusters, la ausencia de una punta clara sugiere que determinar el número ideal de clusters requerirá conocimiento del contexto y del negocio.
Por último, configuramos el algoritmo K-means estableciendo el parámetro ‘n_clusters’ en 5. A continuación, aplicamos el algoritmo a los datos de ‘df’. El método fit_predict() ajusta el modelo KMeans a los datos, asignando cada caso individual del df a uno de los clusters. Las asignaciones de clusters para cada caso individual se almacenan en la variable y_predicted. En el último paso, añadimos una nueva columna llamada ‘Cluster’ al DataFrame df y asignamos los valores de y_predicted a esta columna. Cada valor representa el cluster al que ha sido asignado cada caso individual del df.

Utilizando de nuevo la biblioteca Matplotlib llegamos al final de nuestro ejercicio, generando un gráfico de dispersión en 3D para visualizar los resultados de un análisis de agrupamiento. El código procede a dibujar cada caso individual en el espacio 3D. Cada comando de diagrama de dispersión representa un cluster diferente, donde los casos individuales que pertenecen a un cluster específico se seleccionan utilizando indexación condicional. Los casos se sitúan en el espacio en función de sus atributos «Edad», «Ingresos anuales (k$)» y «Puntuación de compromiso del cliente (CES)» del DataFrame df. A cada grupo se le asigna un color diferente. La función view_init() se utiliza para establecer el ángulo de visión del gráfico 3D, especificando un ángulo de elevación de 15 y un ángulo de acimut de 185. Las etiquetas de los ejes se establecen para el eje X (Edad), el eje Y (Ingresos anuales (k$)) y el eje Z (Puntuación de compromiso del cliente (CES)).
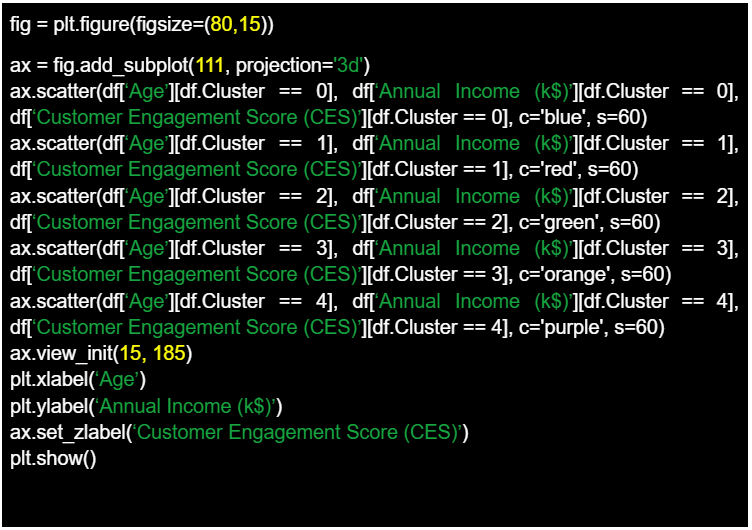
En conjunto, el resultado final es un gráfico de dispersión en 3D que representa visualmente los grupos en función de los atributos edad, ingresos anuales (k$) y puntuación de compromiso del cliente (CES), lo que facilita el análisis y la interpretación. Podemos observar que el gráfico nos muestra 5 grupos distintos con características específicas en función de la distribución de nuestras variables de análisis. En nuestra hipotética investigación sobre un comercio electrónico, la información extraída en este ejercicio debería permitir que el/la investigadora ejecute un muestreo intencional informado teniendo en cuenta las preguntas y objetivos de la investigación, pero también ajustando la fase de captación a los recursos y plazos disponibles.
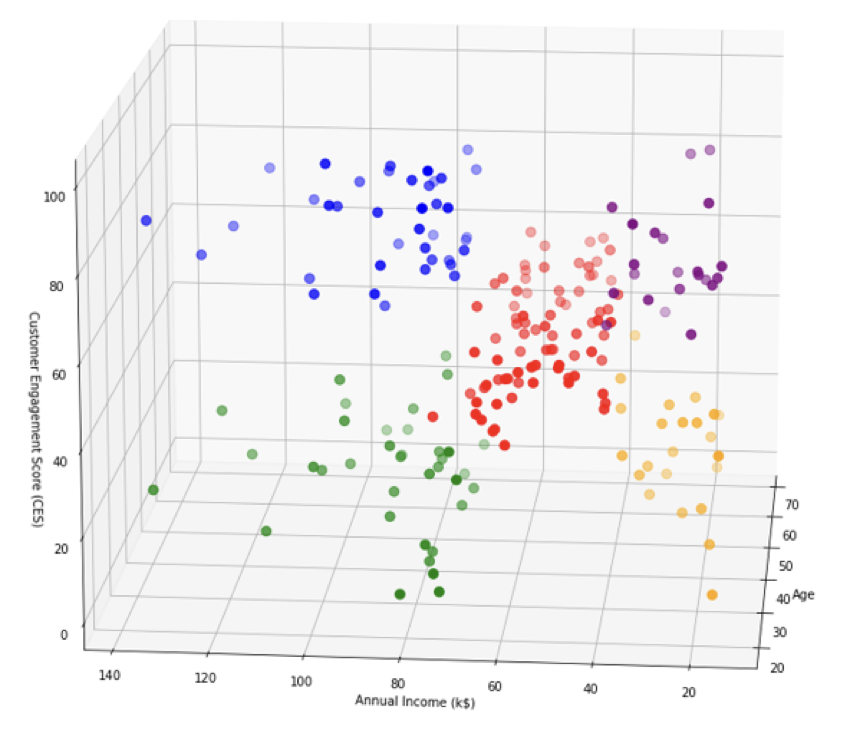
2. Ejecución del muestreo intencional estratificado
Al analizar el gráfico de puntos en 3D, surge un patrón discernible que revela los atributos distintivos presentes en cada uno de los 5 grupos.
- El grupo azul se compone de usuarios del e-commerce de mayor edad, con ingresos anuales altos y elevado CES.
- El grupo verde es similar al azul, aunque se trata de usuarios más jóvenes.
- En cambio, el grupo rojo representa a la población media, que incorpora usuarios de todas las edades junto a los valores medianos tanto de ingresos anuales como de puntuación de CES. En cuanto a los ingresos, oscilan aproximadamente entre 40 y 80; para el valor CES, oscila entre 10 y 60.
- Tanto el grupo naranja como el morado incluyen usuarios con ingresos bajos. No obstante, el factor diferenciador reside en que el grupo naranja indica un CES más bajo y usuarios ligeramente más jóvenes, mientras que el grupo morado señala un CES más alto y usuarios ligeramente más mayores.
Este sencillo análisis podría ampliarse de varias formas. Por ejemplo, incorporando la variable de género y explorando los patrones de composición de género dentro de cada uno de los clusters. Sin embargo, por ahora lo obviaremos y nos concentraremos en las reflexiones finales sobre cómo esta información puede facilitar la fase de captación mediante un muestreo intencional estratificado. La primera y más importante conclusión derivada de este análisis es que el algoritmo por sí solo es incapaz de ejecutar de forma eficiente los procesos de captación. Esto puede parecer obvio tras el ejercicio planteado, pero en el actual contexto de mitificación de la Inteligencia Artificial es necesario remarcar que los algoritmos son sólo herramientas, y no un nuevo método mágico que resuelve los viejos problemas que aquejan a los científicos sociales, humanistas y de experiencia de usuario (Grimmer et al., 2021).
Por lo tanto, el papel del/la investigador/a es esencial en la interpretación del clusterizado para construir hipótesis sólidas, elegir una técnica metodológica cualitativa pertinente y ejecutar un muestreo informado y alineado (Gilbert et al., 2007). Este muestreo debe abordar adecuadamente las preguntas y los objetivos de la investigación, al tiempo que optimizar los plazos y la financiación disponibles. Dependiendo del objetivo final de la investigación, podemos necesitar captar usuarios de cada cluster o, por el contrario, concentrarnos en un uno específico. Esta es la misma línea de argumentación empleada por Nielsen (2000) en su célebre artículo “Why You Need to Test with Only 5 Users». Él también señala que la muestra de 5 usuarios puede variar si detectamos grupos de usuarios muy distintos en nuestro público objetivo. Sin entrar en el debate de si la referencia a 5 usuarios es aplicable a todos los posibles escenarios de investigación, lo que está claro es que contar con un análisis exhaustivo de los subgrupos dentro de nuestro público y las características que los definen nos acerca al objetivo de la saturación teórica.
Conclusiones
Como reflexión final, y de la misma forma que han transformado tantas otras áreas de la vida, el machine learning y los algoritmos tienen un potencial transformador en las ciencias sociales, las humanidades y la investigación en experiencia del usuario. Liberar este potencial implica reconsiderar las convenciones de los algoritmos y reaplicar estas técnicas para llevar a cabo tareas de descubrimiento. Defiendo la postura de Grimmer et al. (2021) cuando mantiene un enfoque agnóstico de la aplicación de técnicas de aprendizaje automático en las disciplinas sociales y humanas. Esto significa que, en muchos casos, no existe un modelo correcto o verdadero que deba utilizarse, y que no hay un único método que pueda utilizarse para todas las aplicaciones de un conjunto de datos. Por el contrario, y como afirman los autores, es el/la investigadora y su perspectiva crítica quienes tienen la responsabilidad de utilizar el método que optimice el rendimiento para cada tarea de investigación concreta. En definitiva, como defienden Chen et al. (2018), este trabajo pretende construir conexiones entre los algoritmos y los enfoques humanísticos y sociales, no sólo para facilitar el proceso analítico, sino, lo que es más importante, para desarrollar un terreno común para ambas disciplinas.




